Cerebra establishes a new benchmark for training largest AI models on a single processor
Cerebras Systems recently announced a milestone of training multibillion-parameter Natural Language Processing (NLP) models, including GPT-3XL 1.3 billion models, GPT-J 6B, GPT-3 13B, and GPT-NeoX 20B, on a single CS-2 system. According to the claims made by Cerebras Systems, a single CS-2 system with a single Cerebras wafer can now train models with up to 20 billion parameters, a feat that has never been accomplished on a single device. A CS-2 machine, around 26 inches tall, may be placed into a typical data center rack.
In NLP, generally larger models trained on a larger amount of data are found to be more accurate. The conventional method of training a large NLP model involved splitting up the model onto a number of GPUs. Cerebras decreases the system-engineering time required to run big NLP models from months to minutes by allowing a single CS-2 to train these models. Additionally, it eliminates one of the most obnoxious NLP features—partitioning the model among thousands or hundreds of tiny graphics processing units (GPUs).
As quoted by Kim Branson, SVP of Artificial Intelligence and Machine Learning at GSK,
“GSK generates extremely large datasets through its genomic and genetic research, and these datasets require new equipment to conduct machine learning. The Cerebras CS-2 is a critical component that allows GSK to train language models using biological datasets at a scale and size previously unattainable. These foundational models form the basis of many of our AI systems and play a vital role in the discovery of transformational medicines.”
The scale and computing power of the Cerebras Wafer Scale Engine-2 (WSE-2) and the Weight Streaming software architectural upgrades made accessible by the introduction of version R1.4 of the Cerebras Software Platform combined to achieve this engineering feat in the field of Artificial Intelligence. Cerebras’ WSE-2 has 2.55 trillion more transistors and has 100 times as many compute cores as the largest GPU, making it the largest processor ever built. Even the biggest neural networks can fit on the WSE-2 due to their size and computing power. Memory and computation are separated by the Cerebras Weight Streaming architecture, allowing memory (which is used to store parameters) to expand independently of computing. So a single CS-2 may handle models with trillions of parameters.
RELATED POSTS
 29 October, 2019 Dual frequency GNSS module enables sub-1m accuracy
29 October, 2019 Dual frequency GNSS module enables sub-1m accuracy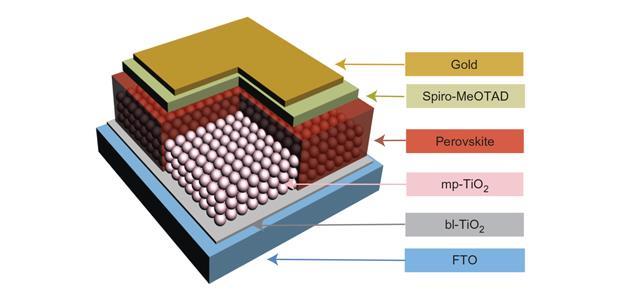 15 December, 2017 Perovskite solar cells stabilized at 19% efficiency
15 December, 2017 Perovskite solar cells stabilized at 19% efficiency 30 July, 2023 AM64 Sitara Series Dedicated to Edge Computing Devices for Industry 4.0
30 July, 2023 AM64 Sitara Series Dedicated to Edge Computing Devices for Industry 4.0 18 May, 2021 Vishay VEML6031X00 high accuracy ambient light sensor supports I2C BUS
18 May, 2021 Vishay VEML6031X00 high accuracy ambient light sensor supports I2C BUS 25 July, 2023 Rogowski-Relief – An Open Source Rogowski Coil Based Current Probe
25 July, 2023 Rogowski-Relief – An Open Source Rogowski Coil Based Current Probe 13 November, 2018 Micro camera module fits space-constrained devices
13 November, 2018 Micro camera module fits space-constrained devices